Motion Picture Standards and Compression Techniques
Here is a list of the
different video coding standards:
Ø MPEG-1: Is the standard of audio and video
compression. Provides video at a resolution of 350x240 at 30 frames per second.
This produces video quality slightly below the quality of conventional VCR
videos. Includes audio compression format of Layer 3 (MP3).
Ø MPEG-2: audio and video standard for broadcast of
television quality. Offers resolutions of 720x480 and 1280x720 at 60fps with
audio CD quality. Matches most of TV standards even HDTV. The principal use is
for DVDs, satellite TV services and digital TV signals by cable. An MPEG-2
compression is able to reduce a 2 hour video to few gigabytes. While
decompressing a MPEG-2 data stream no needs much computer resources, the encoding
to MPEG-2 requires more energy to the process.
Ø MPEG-3: Designed for HDTV but was replaced for MPEG-2
Ø MPEG-4: Standard algorithm for graphics and video
compression based on MPEG-1, MPEG-2 and Apple QuickTime technology. The MPEG-4
files are smaller than JPEG or QuickTime, therefore are designed to transfer
video and images through a narrow bandwidth and sustain different mixtures of
video with text, graphics and 2D or 3D animation layers.
Ø MPEG – 7: Formally called Multimedia Content
Description Interface, supplies a set of tools for multimedia content.
Performed to be generic and not aimed at a specific use.
Ø MPEG –
21: Allow a Rights Expression Language (REL) and
Rights Data Dictionary. Describes a standard that defines the description of
the content and the processes to access, search, store and protect the
copyright of the content discordant with other MPEG standards that define
compression coding methods. The above-mentioned are the standard but each one
has specific parts depending on the use.
Among these types the most important
contemporaneously are:
Ø MPEG-2
Ø MPEG-4 →. Technologically called MPEG-4 H.264 /
AVC.
MPEG-2 (H.262)

MPEG-2 is a standard for “the
generic coding of moving pictures and associated audio information”. Is an
extension of the MPEG-1 international standard for digital compression of audio
and video signals created to broadcast formats at higher bit rates than MPEG-1.
Initially developed to serve the transmission of compressed television programs
via broadcast, cablecast, and satellite, and subsequently adopted for DVD
production and for some online delivery systems, defines a combination of lossy
video compression and lossy audio data compression using the actual methods of
storage, like DVDs or Blu-Ray, without a bandwidth restriction.
The main characteristics are:
Ø New prediction modes of fields and frames for
interlaced scanning.
Ø Improved quantification.
Ø The MPEG-2 transport stream permits the
multiplexing of multiple programs.
Ø New intra-code variable length frame (VLC). Is
a code in which the number of bits used in a frame depends on the probability
of it. More frame probability implies more bits intended by frame. Strong
support for increased errors.
Ø Uses the discrete cosine transform algorithm
and motion compensation techniques to compression.
Ø Provides for multichannel surround sound
coding. MPEG-2 contains different standard parts to suit to the different
needs. Also annexes various levels and profiles.
MPEG-2 FUNDAMENTALS
Nowadays, a TV camera can generate 25 pictures per
second, i.e., a frame rate of 25Hz. But in order to convert it to a digital
television is necessary to digitalize the pictures in order to be processed
with a computer. An image is divided in two different signals: luminance (Y)
and chrominance (UV). Each image has one luma number and two chrominance
components. The television colour signal Red-Green-Blue (RGB) can be
represented with luma and chrominance numbers. Chrominance bandwidth can be
reduced relative to the luminance signal without an influence on the picture
quality.
An image can also be defined
with a special notation (4:2:2, 4:2:0). These are types of chroma sub-sampling
relevant to the compression of an image, storing more luminance details than
colour details. The first number refers to the luminance part of the signal,
the second refers to the chroma. In 4:2:2 luminance is sampled 4 times while
the chroma values are sampled twice at the same rate. Being a fact that the
human eye is more sensitive to brightness than colour, chroma is sampled less
than luminance without any variation for the human perception. Those signals
are also partitioned in Macro blocks which are the basic unit within an image.
A macro block is formed by more blocks of pixels. Depending on the codec, the
block will be bigger or smaller. Normally the size is a multiple of 4. MPEG-2
coding creates data flow by three different frames: intra-coded frames (I
frames), predictive-coded frames (P-frames), and bidirectional-predictive-coded
frames (B-frames) called “GOP structure” (Group of Pictures structure).
Ø I-frame: Coded pictures without reference to others.
Is compressed directly from a original frame.
Ø P-frame: Uses the previous I-frame or P-frame for
motion compensation. Each block can be predicted or intra-coded.
Ø B-frame: Uses the previous I or P picture and offers
the highest compression. One block in a B-picture can be predicted or
intra-coded in a forward, backward or bidirectional way. A typical GOP
structure could be: B1 B2 I3 B4 B5 P6 B7 B8 P9 B10 B11 P12. I-frames codes spatial redundancy while
B-frames and P-frames code temporal redundancy. MPEG-2 also provides interlaced
scanning which is a method of checking an image. The aim is to increase the
bandwidth and to erase the flickering showing the double quantity of images per
second with a half frame rate. For example, produce 50 images per second with a
frame rate of 25Hz. The scan divides a video frame in two fields, separating
the horizontal lines in odd lines and even lines. It enhances motion perception
to the viewer. Depending on the number of lines and the frame rate, are divided
in:
Ø PAL / SECAM: 25 frames per second, 625 lines
per frame. Used in Europe.
Ø NTSC: 30 frames per second, 525 lines per
frame. Used in North America.
MPEG-2 encoding is organized
into profiles. A profile is a "defined subset of the syntax of the
specification". Each profile defines a range of settings for different
encoder options. As most of settings are not available and useful in all
profiles, these are designated to suit with the consumer requirements. A
computer will need a hardware specific for the use, the same with a television
or a mobile phone, but it would be capable to rate it in a particular profile. Then an encoder is needed to finish the
compression.
MPEG-2 COMPRESSION BASICS

Spatial Redundancy:
A technical compression type which consists of
grouping the pixels with similar properties to minimize the duplication of data
in each frame.
Involves an analysis of a
picture to select and suppress the redundant information, for instance,
removing the frequencies that the human cannot percept. To achieve this is
employed a mathematical tool: Discrete Cosine Transform (DCT).
Intra Frame DCT Coding:
The Discrete cosine Transform (DCT) is a based
transform with Fourier Discrete Transform with many applications to the science
and the engineering but basically is applied on image compression algorithms.
DCT is employed to decrease the special redundancy of the signals. This
function has a good energy compaction property and so on accumulates most of
the information in few transformed coefficients. In consideration of this the
signal is converted to an new domain, in which only a little number of
coefficients contain most of the information meanwhile the rest has got
unappreciated values. In the new domain, the signal will have a much more
compact representation, and may be represented mainly by a few transform
coefficients. It is independent of the data. The algorithm is the same,
regardless of the data applied in the algorithm. It is a lossless compression
technique (negligible loss).The DCT is capable to interpret the coefficients in
a frequency point. As a result of that, it can take a maximum of compression
capacity profit. The result of applying DCT is an 8x8 array composed of distinct
values divided in frequencies:
• Low
frequency implies more sensitive elements for the human eye.
• High
frequency means less cognizant components.
Temporal Redundancy:
Temporal compression is achieved having a view
in a succession of pictures.
Situation: An object moves across a picture
without movement. The picture has all the information required until the
movement and is not necessary to encode again the picture until the alteration.
Thereafter, is not necessary to encode again all the picture but only the part
that contains the movement owing that the rest of the scene is not affected by
the moving object because is the same scene as the initial picture. The
notation with is determined how much movement is contained between two
successive pictures is motion compensated prediction.
As a result of isolating a
picture is not a good fact because probably an image is going to be constructed
from the prediction from a previous picture or maybe the picture may be useful
to create the next picture.
Motion
Compensated Prediction:
Identify the displacement of a given macro
block in the current frame respect from the position it had in the frame of
reference.
The steps are:
Ø Search for the same macro blocks of the frame
to be encoded in the frame of
reference.
Ø If there is not the same macro block then the
corresponding motion vector is
encoded.
Ø The more similar macro block (INTER) is chosen
and later on is necessary to
encode the motion vector.
Ø If there is no similar block (INTRA) these
block is encoded using only the spatial redundancy.
H.264 / MPEG-4 AVC
H.264 or MPEG-4
part 10 defines a high-quality video codec compression developed by the Video
Coding Expert Group (VCEG) and the Motion Picture Experts Group (MPEG) in order
to create a standard capable of providing good quality image, but using rates
actually lower than in previous video standards such as MPEG-2 and without
increasing the complexity of its design, since otherwise it would be
impractical and expensive to implement. A goal that is proposed by its
creators was to increase its scope, i.e., allow the standard to be used in a
wide variety of networks and video, both high and low resolution, DVD storage,
etc.

In December 2001
came the Joint Video Team (JVT) consisting of experts from VCEG and MPEG, and
developed this standard to be finalized in 2003. The ISO / IEC (International
Organization for Standardization / International Electro technical Commission)
and ITU-T (International Telecommunication Union-Telecommunication Standardization
Sector) joined this project. The first is responsible of the rules for
standards by focusing on manufacturing and the second focuses mainly on tariff
issues. The latter planned to adopt the standard under the name of ITU-T H.264
and ISO / IEC wanted to name him MPEG-4 Part 10 Advanced Video Codec (AVC),
hence the name of the standard. To set the first code they firstly based on
looking at the previous standard algorithms and techniques to modify or if not
create new ones:
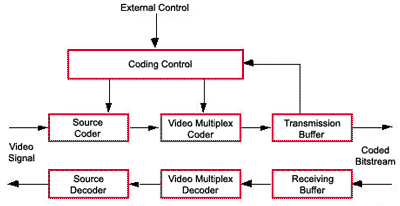
Ø DCT structure in conjunction with
the motion compensation of previous versions was efficient enough so there was
no need to make fundamental changes in its structure.
Ø Scalable Video Coding: An important
advance because it allows each user,
regardless of the limitations of the device, receives the best possible
quality, issuing only a single signal. This is possible because it provides a
compressed stream of video and users can take only what you need to get a
better video quality according to their technical limitations of receipt.
The MPEG-4 has more complex
algorithms and better benefits giving a special quality improvement, which
provides a higher compression rate than MPEG-2 for an equivalent quality.
MAIN ADVANTAGES
For the MPEG-4 AVC the main
important features are:
1. Provides almost DVD quality video, but uses
lower bit rate so that it's feasible to transmit digitized video streams in
LAN, and also in WAN, where bandwidth is more critical, and hard to guarantee.
2. Dramatically advances audio and video
compression, enabling the distribution of content and services from low
bandwidths to high-definition quality across broadcast, broadband, wireless and
packaged media.
3. Provides a standardized framework for many
other forms of media — including text, pictures, animation, 2D and 3D objects –
which can be presented in interactive and personalized media experiences.
4. Supports the diversity of
the future content market.
5. Offers a variety of so-called “profiles,”
tool sets from the toolbox, useful for specific applications, like in
audio-video coding, simple visual or advanced simple visual profile, so users
need only implement the profiles that support the functionality required.
6. Uses DCT algorithm mixed with motion
compensation. It clearly shows that MPEG4 wants to be a content-based
representation standard independent of any specific coding technology, bit
rate, scene type of content, etc. This means it shows at the same time why and
how MPEG4 is different from previous
moving pictures coding standards.
8. Low latency
The most important and relevant are:
1. Reduces the amount of storage needed
2. Increases the amount of time video can be
stored
3. Reduces the network bandwidth used by the
surveillance system
No comments:
Post a Comment